
Olá galera o/
No post de hoje, vamos explorar os conceitos das arquiteturas Lambda e Kappa, amplamente utilizadas em cenários de big data. Vamos entender seus funcionamentos, aplicações e escolher a arquitetura mais indicada para adotar em nossos projetos, levando em conta a individualidade dos clientes. Além disso, vamos aprender quais serviços da cloud azure podem ser utilizados nessas arquiteturas.
Sumário
- O que são essas arquiteturas?
- Arquitetura Lambda
- Arquitetura Kappa
- Serviços da Azure para trabalhar com as Arquiteturas Lambda e Kappa
- Near Real Time é diferente de Real Time
- Considerações Finais
O que são essas arquiteturas?
As arquiteturas Kappa e Lambda são modelos de arquitetura que podemos utilizar para realizar nossos processamentos de dados. Sendo que, a arquitetura Kappa foca em processamento em tempo real contínuo, enquanto a Lambda combina análises em tempo real e em lote (batch).
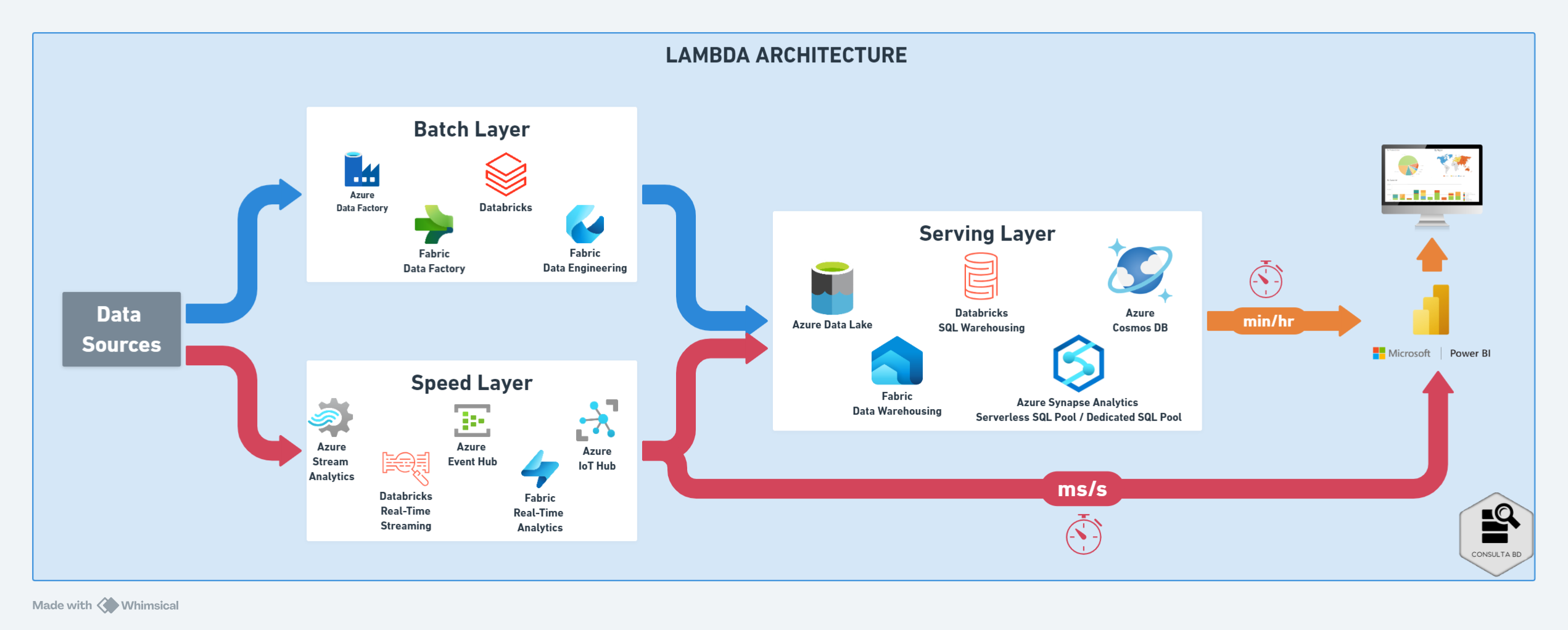
Arquitetura Lambda
A arquitetura Lambda, foi proposta por Nathan Marz em 2011, se destaca por possuir uma abordagem mais tradicional que combina o processamento em tempo real e em lote. Ela foi desenvolvida para lidar com grandes volumes de dados e é amplamente adotada em projetos de big data. Atualmente é a arquitetura mais implementada para projetos que não necessitam de dados em tempo real, ou seja, projetos com processamentos feitos periodicamente (minutos, horas, dias, etc). Essa arquitetura possui 3 fundamentos interessantes, que são as camadas Batch Layer, Speed Layer e Serving Layer. Vamos entende-las um pouco abaixo:
- Batch Layer: Processamento em lote para grandes conjuntos de dados históricos.
- Objetivo: Análises complexas e de longo prazo, como identificação de tendências, padrões e insights valiosos.
- Speed Layer: Processamento em tempo real para dados novos.
- Objetivo: Fornecer insights instantâneos e possibilitar ações imediatas baseado nos dados em tempo real.
- Serving Layer: Armazenar e fornecer acesso aos dados processados por ambas as camadas.
- Objetivo: Centralizar os dados tratados para geração de insights a partir de ferramentas de visualização.
- Quais requisitos de projeto devo analisar para a utilização do Lambda?
- Análises de dados históricos.
- Processamento de dados em Lote com alta escalabilidade.
- Integração com sistemas legados.
- Conformidade com regulamentações e auditorias
- Processamento de dados Estruturados, semi-estruturados e não estruturados.
- Suporte a diversas ferramentas de BI e visualização.
- Custos otimizados para processamento em lote.
- Possibilidade de análises multidimensionais e criação de modelos de machine learning.
- Dados processados com baixa latência, mas não instantaneamente. NEAR REAL TIME.
- Exemplos de Aplicação da Arquitetura Lambda
- Processamento de Dados de E-commerce em Tempo Real
- Análise de Logs de Segurança em Lote
- Geração de Relatórios Financeiros
- Processamento de Dados de IoT em Lote
- Análise de Sentimento de Mídias Sociais em Tempo Real
Arquitetura Kappa
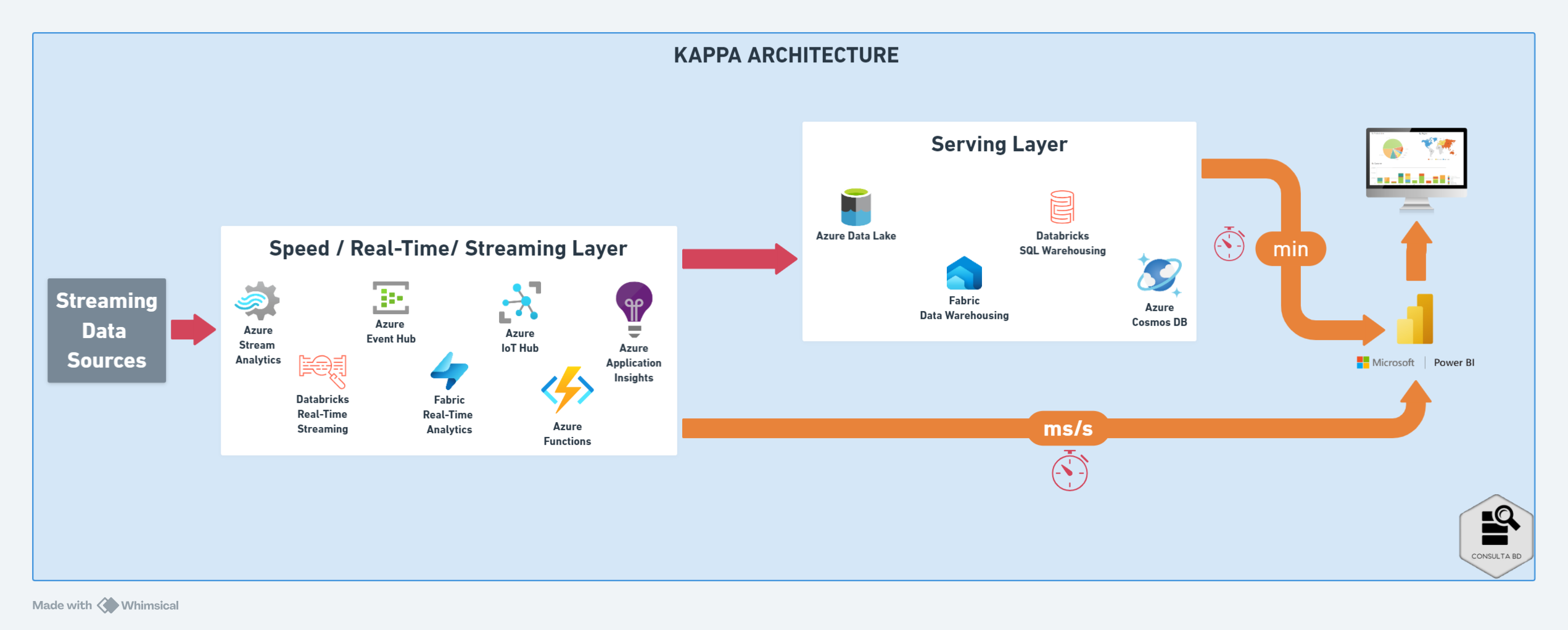
A arquitetura Kappa, proposta por Jay Kreps (co-fundador da Confluent e criador do Apache Kafka) em 2014, se concentra no processamento em tempo real de todos os dados simplificando a arquitetura Lambda ao unificar o processamento em tempo real e em lote em um único caminho de processamento contínuo de dados (streaming). Essa abordagem simplificada utiliza um fluxo único de dados, que geralmente é constituída por 4 etapas:
- Ingestão de Dados: Os dados são coletados de diversas fontes, como sensores, logs, redes sociais e dispositivos IoT, e direcionados para um sistema de ingestão de dados em tempo real.
- Processamento em Tempo Real (kappa layer): No sistema de ingestão, os dados são transformados, filtrados e analisados em tempo real utilizando ferramentas como Apache Kafka, Apache Spark Streaming e Azure Stream Analytics.
- Armazenamento (kappa layer): Todos os dados brutos e processados são armazenados em um data lake, como Azure Data Lake Storage ou AWS Bucket.
- Análise e Visualização: Através de ferramentas de BI (Business Intelligence) e visualização de dados, como Power BI, Qlik Sense ou Tableau, os dados armazenados no data lake podem ser analisados e visualizados para gerar insights.
- Quais requisitos de projeto devo analisar para a utilização do Kappa?
- Necessidade de processamento em tempo real.
- Volume alto de dados em tempo real.
- Simplicidade e agilidade na arquitetura.
- Expertise em ferramentas de processamento em tempo real.
- Alinhamento com os objetivos estratégicos do negócio.
- Custo de Infraestrutura.
- Integridade e consistência dos dados.
- Tempo de resposta para análises e o quão é importânte ter esses dados em tempo real.
- Integração com ferramentas de análise e visualização.
- Exemplos de Aplicação da Arquitetura Kappa
- Monitoramento de Sensores Industriais
- Detecção de Fraudes em Transações Financeiras em Tempo Real
- Análise de Tweets em Tempo Real para Monitorar Tendências e Crise de Reputação
- Detecção de Anomalias em Redes de Computadores para Segurança
- Análise de Dados de Navegação em Aplicativos Móveis
Serviços da Azure para trabalhar com as Arquiteturas Lambda e Kappa
Abaixo segue alguns serviços que podem ser utilizados em cada camada das arquiteturas citadas
- Batch Layer:
- Microsoft Fabric: Data Factory / Data Engineering
- Azure Databricks: Data Ingestion / Data Processing
- Azure HDInsight
- Azure Functions
- Speed / Real-Time / Streaming Layer:
- Azure Event Hubs
- Azure Stream Analytics
- Azure Application Insights
- Microsoft Fabric: Real-Time Analytics
- Databricks: Real-Time Streaming
- Azure IoT Hub
- Azure Application Insights
- Serving Layer:
- Azure Blob Storage (Data Lake)
- Fabric: Data Warehousing
- Databricks: SQL Warehousing
- Azure Cosmos DB
- Azure Synapse Analytics: Serverless SQL Pool / Dedicated SQL Pool
- Visualization Layer:
- Power BI
Abaixo segue um breve descritivo dos serviços utilizados na lista acima.
- Azure Event Hubs: Para ingestão de eventos em tempo real.
- Azure Functions: Para execução de código serverless em resposta a evento, incluindo processamento de dados em tempo real.
- Azure Cosmos DB: Para armazenamento e consulta de dados em tempo real.
- Azure SQL Database: Para armazenamento e consulta de dados estruturados.
- Azure Blob Storage (Data Lake): Para armazenamento de dados estruturados, semi-estruturados enão estruturados.
- Azure Data Factory: Para ingestão, tratamento e orquestração de pipelines de dados em lote.
- Azure Databricks: Para análise e processamento de big data em alta escala.
- Azure Stream Analytics: Para análise em tempo real de dados em fluxo.
- Azure IoT Hub: Para ingestão de dados de dispositivos IoT em tempo real.
- Azure HDInsight: Para provisionamento e gerenciamento de clusters Hadoop, Spark, HBase, entre outros, para análise de big data em lote.
- Azure Data Lake Analytics: Para análise e processamento de big data em lote utilizando consultas SQL.
- Azure Synapse Analytics: Para análise de dados em lote/tempo real e integração com ferramentas de Business Intelligence (BI).
- Azure Application Insights: Para monitoramento e análise de desempenho de aplicativos em tempo real, incluindo análise de logs e métricas.
- Microsoft Fabric: É uma solução de análise multifuncional para empresas que abrange desde a movimentação de dados até ciência de dados, a Análise em Tempo Real e o business intelligence. Ele oferece um conjunto abrangente de serviços, incluindo data lake, engenharia de dados e integração de dados, tudo em um só lugar.
- Power BI: É uma ferramenta de análise de negócios da Microsoft que permite criar visualizações interativas e relatórios de dados de diversas fontes.
Near Real Time é diferente de Real Time
São 2 termos bastante utilizados quando falamos em carregamento de dados em tempo real. Porém, existem diferençaa entre os dois e precisamos entender bem o seu conceito para não sairmos por ai falando besteira e nem vendendo aos clientes modelos de arquiteturas que não vão atender suas necessidades.
Near real time: os dados são processados com baixa latência, mas não instantaneamente. Isso significa que pode haver um pequeno atraso (delay) entre a geração dos dados e a sua disponibilização para análise ou visualização. Este delay pode ser entre segundos e minutos.
Real time: o processamento dos dados ocorre instantaneamente, com latência mínima ou imperceptível. Isso significa que os dados são disponibilizados para análise ou visualização imediatamente após a sua geração.
Considerações Finais
Neste post, exploramos os conceitos das arquiteturas Lambda e Kappa. A escolha entre Kappa e Lambda depende dos requisitos específicos do projeto, como latência de processamento, qualidade dos dados, volume de dados, experiência do profissional ou empresa na implementação dos modelos citados, custo da implementação dos serviços e complexidade de análise dos dados.
Atualmente a arquitetura Lambda é a mais utilizadas nos projetos, por vários motivos, como custos mais acessíveis, não necessidade dos clientes em analisar dados em tempo real, maturidade da empresa, qualidade dos dados, mais profissionais com esta expertise no mercado de tecnologia, entre outros motivos.
Já tenho 12 anos de experiência trabalhando com dados e até o momento não tive oportunidade de trabalhar com projetos em real-time. Sempre que um cliente solicitava um projeto em real-time, eu questionava o real motivo e quase sempre não existia a necessidade de ser real-time. Muitas vezes uma analise 2 vezes ao dia resolvia o problema dele, além disso, eu alertava o mesmo sobre os custos, quem iria realizar a sustentação/manutenção do projeto uma vez que ele fosse entregue pela consultoria, entre outros pontos. Tenham o tato (feeling) de entender as necessidades do cliente antes de sair oferecendo qualquer tipo de implementação de arquitetura.
Lembrando que, não existe o modelo de arquitetura perfeito para o seu projeto, existe a que resolve o problema do cliente. Também existe a possibilidade de combina-las de acordo com os requisitos do projeto. Com essa combinação, é possível obter o melhor dos dois mundos: processamento em tempo real para análises imediatas e processamento em lote para análises retrospectivas e complexas.
Espero que tenham gostado do post, boa leitura e bons estudos.
Quem quiser mandar comentários, sugestões, críticas ou dicas complementares, fiquem a vontade, pois feedbacks positivos ou negativos engradecem meu conhecimento para poder melhorar as postagens para vocês.
Até a próxima o/
Acessem nossas Redes Sociais:

Artigo muito bom!!!
Realmente, conseguir projeto com real time acredito ser raro principalmente devido a questões relacionadas a budget.
CurtirCurtir