
Olá galera o/
No post de hoje, vamos aprender um pouco sobre os Tiers no Azure Data Lake e como eles mexem tanto nos custos quanto no acesso às informações. Além disso, entenderemos o funcionamento do ciclo de vida desse Data Lake.
O que é o Azure Data Lake?
O Azure Data Lake é um serviço de armazenamento altamente escalável oferecido pela Microsoft no Azure, projetado para armazenar e processar grandes volumes de dados, incluindo dados estruturados e não estruturados. Ele fornece um repositório seguro e flexível para armazenar dados brutos, permitindo análises avançadas e processamento de big data. O Azure Data Lake é integrado com ferramentas de análise e aprendizado de máquina, facilitando a obtenção de insights valiosos a partir dos dados.
Para mais informações, consultar documentação do produto: https://learn.microsoft.com/pt-br/azure/storage/blobs/data-lake-storage-introduction
O que são Tiers?
O termo “tier” refere-se ao conceito de armazenamento em camadas, que é uma estratégia de gerenciamento de dados usada para otimizar o custo e o desempenho do armazenamento de dados em nuvem.
Quais são os Tiers disponíveis no Azure Data Lake?
Atualmente o Azure Data Lake possui 3 tiers disponíveis:
Hot tier: O nível Hot é otimizado para dados que são acessados com frequência. Ele tem o melhor desempenho e disponibilidade, mas também é o nível mais caro.
Cool tier: O nível Cool é otimizado para dados que são acessados com menos frequência. Ele tem um desempenho e disponibilidade menores, mas também é o nível mais barato.
Archive tier: O nível Archive é otimizado para dados que são acessados com muito pouca frequência. Ele tem o pior desempenho e disponibilidade, mas também é o nível mais barato.
A escolha do nível de acesso ideal para seus dados depende de suas necessidades específicas de desempenho, disponibilidade e custo. Se você precisar de um desempenho e disponibilidade altos, você deve usar o nível Hot. Tier recomendado para projetos de BI (business Intelligence), big data e data science, pois, os dados estão em constante transformação.
Se você puder tolerar um desempenho e disponibilidade menores, você pode usar o nível Cool para economizar dinheiro, porém, este tier é mais barato para armazenamento estatico. Os custos por transações (leitura, escrita e etc) são mais caras a medida que você utiliza tiers mais baratos em armazenamento.
Se você precisar armazenar dados por um longo período de tempo e não precisar acessá-los com frequência, você deve usar o nível Archive para economizar ainda mais dinheiro.
Abaixo segue uma tabelinha para exemplificar um pouco sobre os Tiers.
| Tier | Desempenho | Disponibilidade | Custo | Aplicação |
|---|---|---|---|---|
| Hot | Melhor | Melhor | Mais caro | Dados acessados com frequência, como arquivos de trabalho, dados analíticos em tempo real e dados de aprendizado de máquina |
| Cool | Menor | Menor | Mais barato | Dados acessados com menos frequência, como arquivos de log, arquivos de backup e dados históricos |
| Archive | Pior | Pior | Mais barato | Dados acessados com muita pouca frequência, como dados de arquivamento e dados de backup de longo prazo |
Tier Cold
O Azure Data Lake agora oferece um novo nível de acesso chamado Cold. O nível Cold é otimizado para dados que são acessados com pouca frequência. Ele tem um desempenho e disponibilidade menores do que o nível Hot, mas também é mais barato.
O nível Cold é uma boa opção para armazenar dados que não precisam ser acessados com frequência, como arquivos de log, arquivos de backup e dados históricos. Ele também é uma boa opção para armazenar dados que podem ser compactados, como arquivos de texto e arquivos de imagem.
O nível Cold é mais barato do que o nível Hot porque é armazenado em um local diferente e tem um nível de replicação diferente.
Para mais informações, consultar documentação do produto: https://learn.microsoft.com/pt-br/azure/storage/blobs/access-tiers-overview
Abaixo segue uma tabelinha para exemplificar um pouco sobre os Tiers atuais e o cold.
| Tier | Desempenho | Disponibilidade | Custo | Aplicação |
|---|---|---|---|---|
| Hot | Melhor | Melhor | Mais caro | Dados acessados com frequência, como arquivos de trabalho, dados analíticos em tempo real e dados de aprendizado de máquina |
| Cool | Menor | Menor | Mais barato | Dados acessados com menos frequência, como arquivos de log, arquivos de backup e dados históricos |
| Cold | Menor ainda | Menor Ainda | Mais barato ainda | Dados acessados com pouca frequência, como dados de arquivamento e dados de backup de longo prazo |
| Archive | Pior | Pior | Mais barato | Dados acessados com muita pouca frequência, como dados de arquivamento e dados de backup de longo prazo |
Você já ouviu falar em ciclo de vida do data lake?
É uma estratégia de gerenciamento de dados que define como os dados são tratados desde a sua criação até a sua exclusão ou arquivamento. O objetivo principal é otimizar o armazenamento, o acesso e o custo dos dados ao longo do tempo. Abaixo estão alguns estágios do ciclo de vida:
- Ingestão de Dados: Neste estágio, os dados são criados ou importados para o Azure Data Lake. Isso pode incluir a captura de dados em tempo real, a importação de arquivos existentes ou a ingestão de dados de fontes externas.
- Armazenamento: Os dados recém-ingestados são inicialmente armazenados na camada HOT para garantir um acesso rápido e baixa latência. Isso é adequado para dados ativamente usados.
- Análise e Processamento: Durante este estágio, os dados são processados, transformados e analisados usando ferramentas de big data e análise de dados disponíveis no Azure. Isso permite extrair insights e valor dos dados.
- Tiring (Movimentação de Dados): À medida que os dados envelhecem ou se tornam menos ativos, você pode configurar políticas de ciclo de vida para mover automaticamente os dados da camada HOT para a camada COOL. Isso ajuda a otimizar custos de armazenamento, pois a camada COOL é mais econômica.
- Retenção e Exclusão: Conforme necessário, você pode definir políticas de retenção para garantir a conformidade com regulamentações e regras de negócios. Isso também pode envolver a exclusão de dados que já não são necessários.
- Arquivamento: Para dados que precisam ser retidos por longos períodos, você pode arquivá-los em um armazenamento de longo prazo, como o Azure Blob Storage ou outro repositório de arquivamento. Os dados são movidos para a Camada ARCHIVE.
Este processo é muito relevante em cenários de big data, análise avançada e retenção de dados a longo prazo. Estratégia deve ser estudada e analisada antes de ser aplicada, é sempre importante consultar o cliente e o arquiteto de dados da empresa antes de aplicar este procedimento.
Como aplicar o estratégia de ciclo de vida no Azure Data Lake!
Para aplicar o processo de gerencimaneto do ciclo de vida no azire data lake siga os seguintes passos:
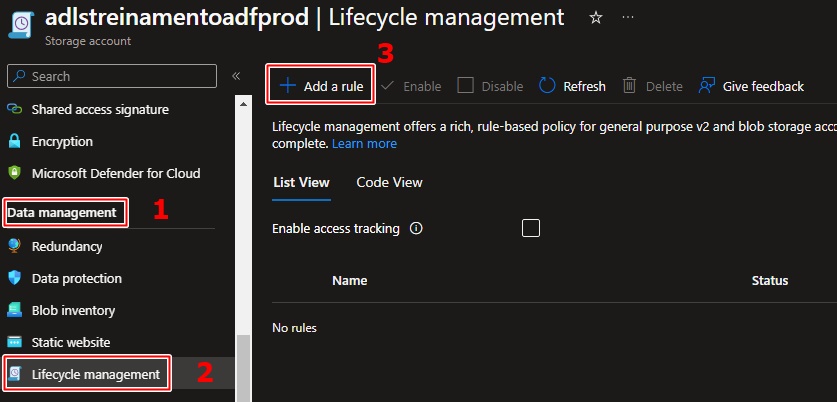
1 – Com o data lake aberto, vá até a seção Data Management.
2 – Selecione a opção Lifecycle management.
3 – Clique em + Add a rule para criar sua regra de ciclo de vida.
Irei fazer o processo mais detalhado em outro post.
Considerações Finais!
Neste post, compreendemos a dinâmica dos tiers, sua relevância para nossas estratégias de gerenciamento de armazenamento e controle de custos no ambiente do Data Lake. Além disso, exploramos um pouco sobre o ciclo de vida no contexto do Azure Data Lake, destacando sua importância para o gerenciamento eficaz de dados ao longo do tempo.
Espero que tenham gostado, boa leitura e bons estudos.
Quem quiser mandar comentários, sugestões, críticas ou dicas complementares, fiquem a vontade, pois feedbacks positivos ou negativos engradecem meu conhecimento para poder melhorar as postagens para vocês.
Até a próxima o/
Acessem nossas Redes Sociais:
